Aconteceu no dia 9 de Setembro em sedes espalhadas por todo o país a etapa regional da Maratona de Programação. O resultado completo pode ser conferido aqui. Em 2017 a sede Goiânia recebeu 27 equipes de 7 instituições de todo o estado, sendo que 6 dessas equipes competiam pela modalidade café-com-leite. As 10 melhores equipes podem ser vistas na imagem abaixo.
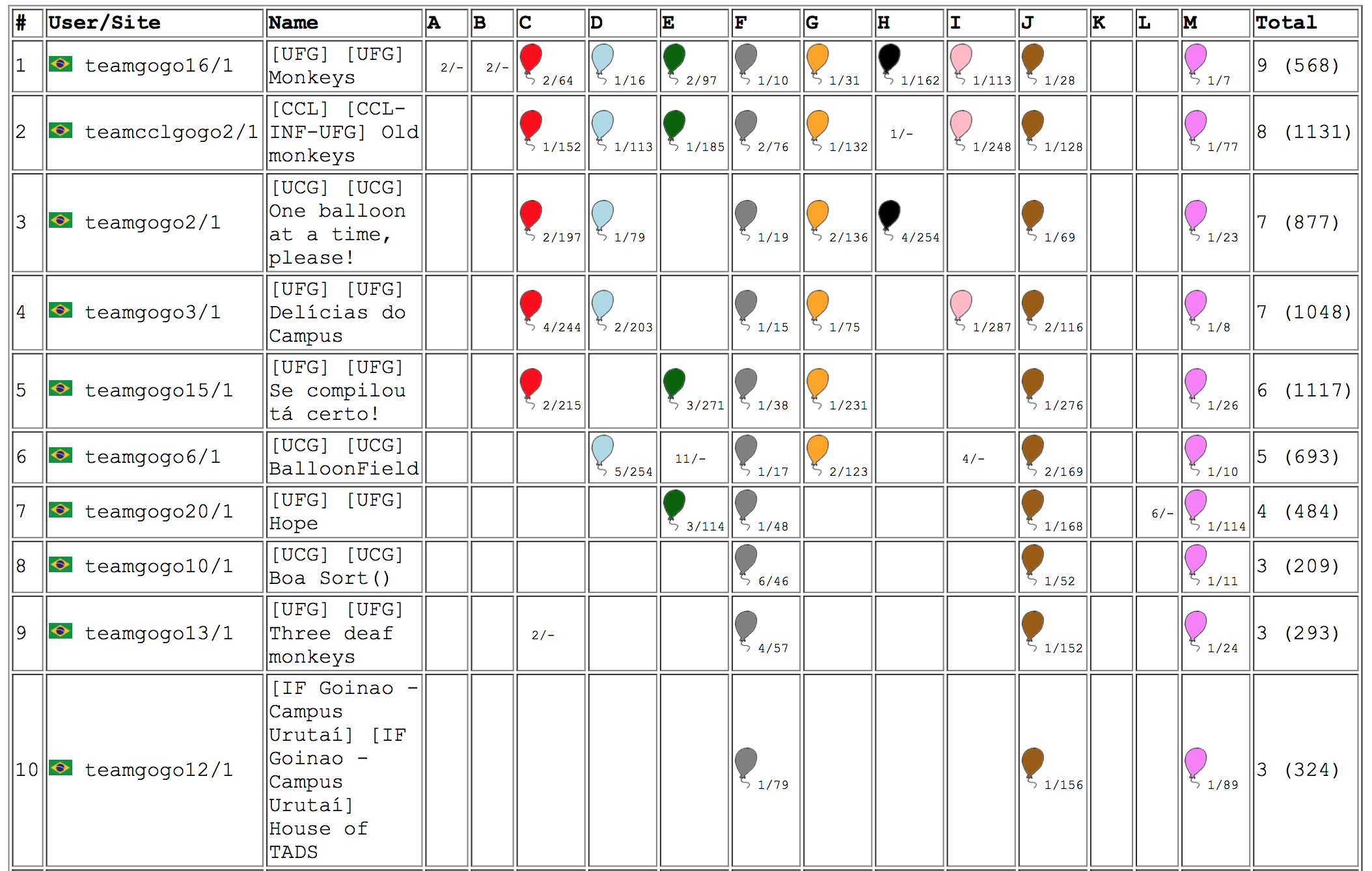
As equipes “Monkeys” do INF-UFG e “One balloon at a time, please!” da PUC-GO se classificaram para a fase nacional da maratona que acontecerá nos dias 10 e 11 de Novembro em Foz do Iguaçu. Boa sorte aos competidores!
A prova esse ano foi composta por 13 problemas, sendo ela resolvida por completo em 3 horas pela equipe ¯\( “/ )/¯ da USP. Confira abaixo a lista.
| Problema | Dificuldade | Técnica relacionada |
|---|---|---|
| A - Acordes Intergaláticos | fácil/médio | segment tree |
| B - Brincadeira | fácil/médio | implementação, pigeonhole principle |
| C - Cigarras periódicas | fácil | matemática, mmc |
| D - Despojados | fácil/médio | matemática, divisibilidade, fatoração |
| E - Escala musical | fácil | ad hoc |
| F - Fase | balão++ | ad hoc |
| G - Ginástica | fácil/médio | programação dinâmica |
| H - Hipercampo | fácil/médio | geometria, programação dinâmica |
| I - Imposto Real | fácil | grafos, dfs |
| J - Jogo da Boca | fácil | game theory |
| K - K-ésimo | médio | matemática |
| L - Laboratório de Biotecnologia | médio/difícil | FFT |
| M - Máquina de Café | balão++ | ad hoc |
A - Acordes intergaláticos
Resolva este problema: URI
Podemos usar uma segment tree com lazy propagation para simular de forma eficiente cada acorde. Armazenamos em cada nó a frequência que cada nota no intervalo representado pelo nó. Podemos então, a cada acorde tocado, computar qual a nota mais frequente e atualizar o entervalo em seguida. Um problema similar apareceu na regional de 2011: Homem, Elefante e Rato.
Um exemplo de implementação segue abaixo:
B - Brincadeira
Resolva este problema: URI
Uma maneira bastante popular de calcular somas de intervalos em vetores estáticos é usando somas de prefixos. Para simplificar, assumimos que o vetor \(A\) é indexado a partir de 1. Definimos então um vetor \(P\), tal que \(P_0 = 0\) e \(P_i = \sum_{j=1}^{i}A_j\). Desse modo podemos obter a soma do intervalo \([i, j]\) como \(P_j - P_{i-1}\). Usando essa representação e o Princípio da casa dos pombos podemos provar que sempre existe uma subsequência contígua cuja soma dos elementos é divisível por \(X\).
Se calcularmos os valores \(P_i\) módulo \(X\) existem apenas \(X\) possíveis valores. Logo, a partir do elemento \(P_X\), garantidamente teremos valores repetidos. Isso significa que sempre seremos capazes de encontrar dois índices \(L\) e \(R\) distintos tais que \(P_L = P_R\). Sendo assim sempre poderemos encontrar um intervalo \([L+1, R]\) cuja soma dos elementos é divisível por \(X\), visto que \(P_R - P_{L+1-1 = L} = 0\).
Basta, então, gerar os elementos da sequência e manter a soma do prefixo (módulo \(X\)) visto até o momento, armazenando a posição da primeira ocorrência de cada valor. Ao encontrarmos um valor que já foi visto antes, verificamos se a distância entre as posições é maior ou igual a \(Y\), imprimindo tais índices em caso positivo. Com essa estratégia garantimos também que vamos obter o menor valor para os inteiros \(I\) e \(F\) que representam os índices do primeiro e do último elementos da subsequência contígua escolhida.
Um exemplo de implementação segue abaixo:
C - Cigarras Periódicas
Resolva este problema: URI
O primeiro passo é notar que a quantidade de iterações necessária até que os ciclos de vida coincidam é o mínimo múltiplo comum dos ciclos de todas as populações em questão. Como queremos que o resultado respeite o limite superior \(L\) não faz sentido que a nova população tenha um ciclo de vida maior que \(L\). Assim, basta calcular o mínimo múltiplo comum das populações existentes com todos os valores de 1 a \(L\) e imprimir o valor que gerou o melhor resultado.
Um exemplo de implementação segue abaixo:
D - Despojados
Resolva este problema: URI
Dada a fatoração em números primos de um valor \(N = p_1^{e_1} \times p_2^{e_2} \times \dots \times p_k^{e_k}\). Um número \(D\) é divisor de \(N\) se e somente se em sua fatoração não existe um número primo que não está presente nos fatores de \(N\) e os expoentes dos fatores de \(D\) são todos menores ou iguais ao expoente do fator correspondente de \(N\).
Assim, considerando a definição de número despojado, podemos ver as fatorizações dos divisores despojados de \(N\) como números da forma \(p_1^{d_1} \times p_2^{d_2} \times \dots \times p_k^{d_k}\), onde \(d_i \in {0, 1}\). Com isso basta calcular o número de fatores primos de \(N\) e computar o número de combinações equivalentes a divisores despojados. Esse valor, se a quantidade de fatores primos distintos for igual a \(K\), é dado por \(2^K - (K+1)\). Ou seja, calculamos todas as combinações e desconsideramos aquelas com apenas 0 ou 1 elementos.
Um exemplo de implementação segue abaixo:
E - Escala Musical
Resolva este problema: URI
Para começar, simplificamos a entrada, transformando cada uma das notas da música na nota básica correspondente. Cada uma das 12 notas básicas pode ser usada para definir um tom maior. Cada tom maior é composto por 7 notas, que podem ser encontradas seguindo o padrão descrito no enunciado do problema. Para verificar se a música está ou não em um tom maior devemos conferir se todas as notas que aparecem na música fazem parte do mesmo. Isso quer dizer que nem sequer precisamos armazenar todas as notas da música, basta marcar quais notas foram vistas. Podemos então testar cada uma das notas básicas, em ordem, como base para o tom maior, imprimindo assim que encontramos o primeiro tom maior em que a música se encontra ou desafinado caso a música não esteja em nenhum tom maior.
Um exemplo de implementação segue abaixo:
F - Fase
Resolva este problema: URI
Basta ordenar as pontuações em order decrescente. Começamos com resposta = k e incrementamos enquanto houverem elementos e a pontuação na posição resposta for igual a pontuação na posição resposta - 1.
Um exemplo de implementação segue abaixo:
G - Ginástica
Resolva este problema: URI
Esse problema pode ser resolvido com programação dinâmica (se não conhece a técnica pode começar por aqui ou aqui). Para simplificar podemos Seja \(F(t, d)\) o número de programas com \(t\) minutos tais que a dificuldade do último exercício é \(d\). O número total de programas que estamos interessados pode ser calculado como:
\[R = \sum_{d=M}^{N}{F(T, d)}\]Podemos calcular \(f(t, d)\) usando a recorrência: \(f(t, d) = \begin{cases} 1, & \text{se $t = 1$,} \\ f(t-1, d+1), & \text{se $d = M$,} \\ f(t-1, d-1), & \text{se $d = N$,} \\ f(t-1, d-1) + f(t-1, d+1) , & \text{caso contrário.} \\ \end{cases}\)
Um detalhe é que para calcular \(F(t, \dots)\) só precisamos dos valores de \(F(t-1, \dots)\) então podemos usar uma matriz com apenas duas linhas. Além disso também é possível considerar as dificuldades como \([1, N-M+1]\) no lugar de \([M, N]\).
Um exemplo de implementação segue abaixo:
H - Hipercampo
Resolva este problema: URI
Podemos construir um grafo direcionado onde cada vértice representa um ponto. Nesse grafo existe uma aresta ligando um vértice \(u\) a um vértice \(v\) se o ponto representado por \(v\) está dentro do triangulo definido pelas âncoras (\(A\) e \(B\)) e pelo ponto representado por \(u\). É fácil perceber que nesse grafo não haverão ciclos, logo o problema se reduz a encontrar o maior caminho em um DAG.
Uma abordagem parecida mas que dispensa a conexão com o problema do maior caminho em um DAG é ordenar os pontos de acordo com o valor da coordenada \(y\) e usar programação dinâmica. Um ponto cujo valor de \(y\) é maior ou igual ao valor de \(y\) de um ponto \(i\) não pode estar dentro to triangulo definido pelas âncoras e o ponto \(i\). Definimos \(dp[i]\) como a maior quantidade de pontos ligados as ancoras tal que o ponto com a maior coordenada \(y\) é \(i\). Para calcular \(dp[i]\) basta olhar os pontos \(j < i\).
Um exemplo de implementação segue abaixo:
I - Imposto Real
Resolva este problema: URI
O grafo descrito no problema se trata de uma árvore enraizada no vértice \(1\). Assim, todo o ouro coletado nos vértices da subárvore enraizada em um vértice \(v\), deve passar pela cidade \(v\) antes de chegar a capital. Com isso, o fato dos cofres em cada cidade terem capacidade de armazenar todo o ouro viabiliza uma abordagem gulosa. Começando pelas folhas da árvore transferimos todo o ouro para o vértice pai, sempre levando o máximo que a carruagem suporta em uma viagem. Não é possível transferir o ouro percorrendo uma distância menor já que a única forma de levar o ouro da folha \(f\) para a raíz passar pelo pai de \(f\). Levar o ouro direto para a raiz ou sem avaliar as outras folhas primeiro é inútil pois a diferença caso façamos isso está apenas no fato de que dessa forma não fazemos o melhor uso da capacidade da carroça, deixando de levar mais ouro em uma única viagem (e potencialmente aumentando o número de viagens necessárias). Assim, é possível calcular a resposta com uma simples busca em profundidade.
Um exemplo de implementação segue abaixo:
J - Jogo de Boca
Resolva este problema: URI
Podemos olhar para o jogo de uma forma diferente, ao invés de adicionar 1 ou 2 até alcançar \(N\), podemos começar com \(N\) e ir subtraindo \(1\) ou \(2\). Assim temos um jogo de subtração para o qual podemos classificar as posições em vencedoras (\(V\)) e perdedoras (\(P\)) como descrito aqui.
| \(N\) | 1 | 2 | 3 | 4 | 5 | 6 | \(\dots\) |
|---|---|---|---|---|---|---|---|
| posição | \(\bbox[#6f6,border:.5px black,10px]{V}\) | \(\bbox[#6f6,border:.5px black,10px]{V}\) | \(\bbox[#f66,border:.5px black,10px]{P}\) | \(\bbox[#6f6,border:.5px black,10px]{V}\) | \(\bbox[#6f6,border:.5px black,10px]{V}\) | \(\bbox[#f66,border:.5px black,10px]{P}\) | \(\dots\) |
Analisando as primeiras posições é possível perceber que a classificação tem um padrão cíclico. Além disso, cada posição vencendora alcança um única posição perdedora. Com essas duas observações é possível perceber que o problema se resume a calcular o resto da divisão de \(N\) por 3. Um detalhe é que o valor de \(N\) pode ser até \(10^{100}\) logo não podemos usar tipos de dados inteiros em C++ ou Java. Uma alternativa é representar o número como string e calcular o resto da divisão na mão. Outra alternativa, talvez um pouco melhor, era aproveitar o fato de que Python agora faz parte das linguagens disponíveis e resolver o problema em uma única linha de código: print(int(input())%3).
Um exemplo de implementação segue abaixo:
K - K-ésimo
Resolva este problema: URI
Como só estamos interessados na parte inteira de \(X^N\) onde \(X = A + \sqrt{B}\), se conseguirmos nos livrar da raiz quadrada e trabalhar apenas com inteiros, podemos calcular \(X^N \bmod 10^5\). Dessa forma seria possível usar apenas tipos de dados básicos para encontrar a resposta. Uma primeira tentativa é usar o Binómio de Newton para tentar se livrar da raiz quadrada. O resultado é \(\sum_{K=0}^{N}{\binom{N}{K}A^{N-K}\sqrt{B}^K}\). Infelizmente isso não ajuda muito já que ainda temos \(\sqrt{B}^K\) com valores impares de \(K\).
Uma outra restrição no enunciado que certamente não está lá sem motivo é que \(-1 < A - \sqrt{B} < 1\). Será como essa restrição pode nos ajudar? Ao olharmos pra expansão de \((A - \sqrt{B})^N\) obtemos \(\sum_{K=0}^{N}{\binom{N}{K}A^{N-K}(-1)^K\sqrt{B}^K}\). Aqui podemos observar algo interessante, ao olhar para a soma \((A + \sqrt{B})^N + (A - \sqrt{B})^N\), se expandirmos as potências dos binómios os termos com \(K\) ímpar irão se cancelar, já para valores impares de \(K\) temos que \(-1^K = -1\). Assim chegamos a \(Z = (A + \sqrt{B})^N + (A - \sqrt{B})^N = 2\sum_{K=0}^{\lfloor\frac{N}{2}\rfloor}{\binom{N}{2K}A^{N-2K}B^K}\). \(Z\) é um valor inteiro que esperamos ser capazes de calcular sem dificuldade, isso já ajuda um pouco. Outro ponto é que \(-1 < A - \sqrt{B} < 1 \implies -1 < (A - \sqrt{B})^N < 1\), logo a parte inteira de \((A + \sqrt{B})^N\) é igual a \(Z\) ou \(Z-1\), o que pode ser determinado apenas olhando para a paridade de \(N\) e os valores de \(A\) e \(B\).
A abordagem parece promissora, tirando o fato de que \(N \leq 10^9\) não permite que calculemos \(Z = (A + \sqrt{B})^N + (A - \sqrt{B})^N\) com complexidade de tempo linear. Para contornar essa dificuldade podemos tentar encontrar uma recorrência linear tal que \(F(N) = (A + \sqrt{B})^N + (A - \sqrt{B})^N\) e com isso usar exponenciação de matrizes para calcular \(F(N)\) em tempo logarítmico.
Se calcularmos os primeiros valores de \(F(N)\) em função de \(A\) e \(B\) temos que:
\[F(0) = 2\] \[F(1) = 2A\] \[F(2) = 2(A^2 + B)\] \[F(3) = 2(A^3 + AB)\]Nesse ponto podemos dar um chute de que nossa recorrência é da forma \(F(N) = C \times F(N-1) + D \times F(N-2)\) (ou primeiro chutamos \(F(N) = C \times F(N-1) + D\) e partimos pra segunda tentativa ao não chegar a lugar algum). Aqui conseguimos um sistema de equações onde:
\[F(2) = C \times F(1) + D \times F(0)\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ F(3) = C \times F(2) + D \times F(1)\] \[2(A^2 + B) = C \times 2A + D \times 2\ \ \ \ \ \ \ \ \ \ \ 2(A^3 + AB) = C \times 2(A^2 + B) + D \times 2A\]Com isso encontramos \(C\) e \(D\) em função de \(A\) e \(B\), sendo que \(C = 2A\) e \(D = B - A^2\). Agora basta utilizar exponenciação de matrizes para calcular o resultado de \(F(N) = 2AF(N-1) + (B - A^2)F(N-2)\).
Um exemplo de implementação segue abaixo:
L - Laboratório de Biotecnologia
Resolva este problema: URI
A solução para esse problema é descrita detalhadamente no artigo Finding submasses in weighted strings with Fast Fourier Transform.
Resumidamente, definimos \(p_i\) como a submassa da subcadeia formada por \(s_1 s_2 \dots s_i\). Com isso criamos dois polinômios \(P\) e \(Q\). O polinômio \(P\) é definido por \(\sum_{i=1}^n{x^{p_i}}\) enquanto o polinômio \(Q\) é definido por \(\sum_{i=1}^{n-1}{x^{p_n-p_i}}\). Como a submassa de uma subcadeia \([i, j]\) pode ser calculada pela subtração das submassas dos prefixos \((p_j - p_{i-1})\), ao calcular o polinômio \(C = P \times Q\), podemos identificar quais submassas aparecem olhando para os coeficientes de \(C\), já que eles são gerados a partir de todas as combinações dos coeficientes de \(P\) e \(Q\).
Para calcular a multiplicação entre \(P\) e \(Q\) de forma eficiente usamos FFT.
Um exemplo de implementação segue abaixo:
M - Máquina de Café
Resolva este problema: URI
Basta fixar cada andar como o andar onde a máquina de café sera instalada.
Um exemplo de implementação segue abaixo:
Cross-post from paulocezar.net.